专访|蚂蚁金服MISA:比用户更懂自己的自然语言客服系统
2018-05-15 11:42 来源:科技讯
作者:邱陆陆
当手机取代了钱包,支付宝甚至比现金更常用,与蚂蚁金服的产品端一同忙碌起来的还有公司的服务端。95188服务热线就是其中之一。
然而当我们谈起客服电话,想到的仍然是传统的按键菜单(「普通话服务请按1,for English service please press 2」)和在机械而漫长的语音播报里等待的焦躁。「在过去的统计里,只要用户没转接人工,就算作『问题被自助解决了』,其实在我们看来那不叫『解决』,叫『损耗』。」蚂蚁金服的产品运营专家弈客说。秉承着这样的理念,团队开发了MISA(Machine Intelligence Service Assistant),一个能够通过识别用户的语音中包含的业务需求来直接进行回应的客服系统,他们称之为「37摄氏度的自助语音交互」。
在金融业务领域,客户服务涉及许多环节,通过人工智能的技术解决客服问题,为广大用户提供高效、个性化的普惠金融服务,成为金融科技领域非常基础、非常具有挑战性的课题。
最近,在蚂蚁金服发起的「ATEC蚂蚁开发者大赛——人工智能大赛」上,这支团队在初赛就拿出了来自实际应用场景的10万对标注问题集,并开放相关资源与专家指导,邀请人工智能开发者来挑战「问题相似度计算」这一客服领域最基础也最核心的任务。
如今,赛事已经集结了来自全球超过两千支队伍报名,并开启了激烈的准确率打榜竞赛。近日机器之心也有幸探访蚂蚁金服,采访了MISA团队中的三位核心成员:人工智能部资深算法专家深空(张家兴)、客户服务及权益保障事业部产品运营专家弈客(于浩淼)以及人工智能部算法专家千瞳(崔恒斌),聊了聊如何利用深度学习算法构建能够「未卜先知」的客服系统。以下内容根据采访实录整理,机器之心对内容作了不改变原意的调整。
MISA的「成长故事」与「近照」
机器之心:开发MISA系统的初衷是什么?
弈客:95188支付宝服务热线是一个典型的 IVR 场景(Interactive Voice Response,互动式语音应答),作为一个语音渠道,它的业务目标很简单,就是「定位用户的问题,匹配相应解答方案」。一开始,它就是一个传统的按键菜单,后来随着蚂蚁金服业务线的日益增长,按键菜单无法满足业务需求,同时语音识别技术也进入了一个基本可以投入应用的阶段,所以从16年初开始,我们和算法工程师一起,尝试找新的解决方法。
最初的想法是让用户描述自己的问题与场景,然后将描述与我们的业务与知识进行一次匹配。后来,我们发现单次匹配也很难做到特别精准,因为用户很难在单次描述里给出全部所需要素,所以就尝试以多轮交互的形式,用一个对话系统来帮助用户补全其描述中缺失的部分。
再后来,我们发现与其让用户完全清楚地描述自己的问题,不如我们率先发问。我们做了大量的市场调研,发现如今市面上的客服系统也基本上以「描述与匹配」模式为主,涉及多轮交互的本身就很少,在多轮基础上发展方向也没有那么明确。因此我们就回到了蚂蚁自身。我们就想,能不能基于用户在提问时所积累的行为特征,以「猜问题」的形式让系统率先发起对话,降低用户的使用难度。相比于「你有什么问题?」,「你是不是想问XXX问题?」就要容易回答得多,即使用户回答「不是」,我们的问题也会为他接下来的描述提供一个示例。
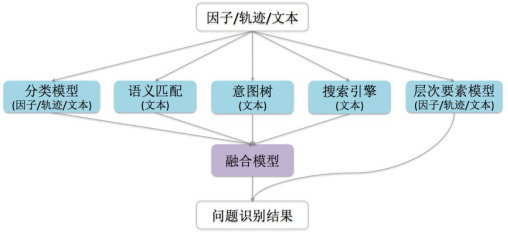
机器之心:反问交互是如何实现的?
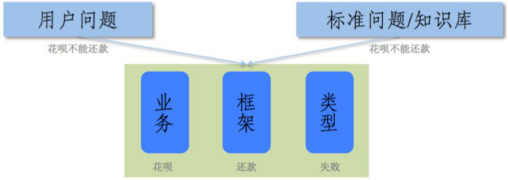
弈客:如今一百通电话里,有三十通会率先通过猜问题的形式对用户进行发问。如果没有猜中,就要思考如何在较短的轮数内摸清用户的需求。用户的大多数问题都能够以「业务、框架、类型」三要素方式进行拆分。例如「花呗不能还款」,「花呗」就是涉及的业务,问题的核心动词「还款」就是框架,「失败」是导致用户提问的诉求类型。有超过一千个用户问题都可以被拆解成三要素的形式,其中包括一百多类业务、不到一百类框架和不超过十种问题类型。
三要素拆分方式的方式能够帮助快速缩小识别范围。用户在描述中,可能不能一次把三要素都描述清楚,但是如果给出了某部分要素,比如用户说「我要还款」,就给出了框架「还款」和类型「如何」,这时我们就可以就缺失的「业务」要素进行反问,比如,「您是要进行花呗还款、借呗还款还是信用卡还款?」
千瞳:从技术的角度上来讲,我们在构建了语义要素库之后,是可以实现 zero-shot 的问题识别的。即,不需要见到特定的要素组合的训练样本,只要在其他训练样本中见过单独的要素在其他场景下出现,一样可以识别这个要素组合,对应到相应问题。
另外,我们也构建了多任务学习的框架。三要素识别任务的目标是非常类似的,都可以看做是多分类问题。多任务学习让不同任务间的数据可以共享。虽然每一个单独的任务都有足够的数据,但是不同任务间目标会让特征提取各有侧重,提高模型效果。相比单模型,识别准确率可以提升7个百分点。
机器之心:如何评估匹配的精确程度?这些评估是否会反过来影响模型的优化?
千瞳:匹配的评估指标有多个层级,第一个是CTR(Click Through Rate),比如在「猜问题」阶段,用户会确认系统猜的是不是他的问题。第二个是分流的准确率,如果分配到人工还有小二派单准确率,最后是问题解决率。
至于用户的评估如何影响模型优化,一言以蔽之,用户的反馈就是模型的训练数据,系统自己能形成一个闭环迭代体系。MISA的大部分模型一周迭代两次。
关于比赛:客服领域里的相似度计算
机器之心:比赛中的「判断两句话是否为同义句」任务和利用分类法进行问题识别任务之间的关系是什么?
深空:当我们拿到一个用户的自然语言问句,想判断它是知识库里的哪一类问题时,通常有两种做法:一是做分类,也就是上面讲到的问题识别;还有一种做法就是判断同义句,给出每一类问题的几条例句后,当一个新的问句出现,就计算新问句与每一条例句之间的相似度。
相比于识别,同义句是一类相对昂贵但具有重大意义的做法。对于许多拿不到丰富数据的场景来说,训练分类器变得不可能,而搜集例句、计算相似度相较之下更为可行和合适。
基于相似度计算的分类算法对于数据的需求要灵活得多,可以根据数据的情况分层次安排:有的方法可以不需要训练数据,基于规则来做;有的方法可以基于领域无关的、有公开语料的通用数据进行训练;当然,如果提供领域相关的数据,可以让相似度计算得更好,就像我们这次提供的数据这样。
从工程的角度来讲,这种一开始对训练数据依赖较小的办法,有利于工程师按部就班把一个问题解决掉。
机器之心:选择判断同义句作为本次大赛赛题的原因都有哪些?
深空:第一,在将用户的问句分类的场景下,相似度计算是一种基础而实用的做法。在客服领域里,大多数应用场景仍然是缺少数据的。第二,问题的相似度计算在其他场景下也有广泛的应用,例如,在「挖掘用户常见问题」任务里,就要对用户问句进行聚类,将每一类常见问题归为一类。聚类的基础就是计算每两个问句之间的相似度。还有许多其他类似的应用。总而言之,相似度计算是客服大领域中非常基础、非常核心的一个问题。
这次比赛的重点就是鼓励选手找到好的相似度计算方法。本次我们在初赛就提供了10万条数据。作为对比,现在的相似度计算比赛中最大的公开数据集大概在1万条左右。但是我们不强制选手使用提供的数据,完全不基于数据或者引入外部数据的做法都是被允许的,希望选手们不拘一格,找到最好的相似度计算方法。
机器之心:是否会考虑将比赛中出现的做法投入到实际生产中?
千瞳:这是肯定的。蚂蚁的业务发展非常快,因此在设计算法的过程中会遇到很多现实的问题:比如用户描述口语化、描述多样性、纠错以长句问题等等,都需要相似度计算方法去解决,我们自己也在进行大量相似度计算方面的探索,希望能够和选手们一起,找到最合适的方法。
2020年澳大利亚旅游局中国区线上旅业洽谈会盛大开幕
【2020 年12月1日, 上海】 2020年 澳大利亚旅游局中国区线上旅业洽谈会(Australia Marketplace Online - China 2020,简称AMO)于...
第二届南京国际艺术博览会落幕:一期一会的艺样金陵
2020年11月29日,为期四天的第二届南京国际艺术季暨南京国际艺术博览会圆满落幕。...
名家推荐:画家王志坚作品赏析
王志坚:生于1958年,湖南湘乡人。毕业于湖南师大美术学院,代表作曾获中国美协授予的二等奖,国家文化部银奖,...
品山崎之韵,溯日威之源
11月4日,三得利日本威士忌世家在上海举办“山崎日威之源”品鉴会,以山崎多个珍贵酒款打造了一场味觉盛宴,与...
笔墨灵动 富力清新:著名画家刘新华
刘新华,天津市人。籍贯:河北河间市。毕业于日本京都艺术大学大学院、文学硕士、美术硕士、美学博士。...
打卡设计|魔都明珠塔前的“Rolf Benz名伶”
▲坐标:上海外滩悦榕庄 热情时尚的Ms.Mio Mio的美如同奥黛丽赫本,略带复古气息却时尚感永存,并拥有自己独立的审...
Ember推出限量版智能温控马克杯, 为中国消费者打造顶级咖啡体验
Ember亮相星巴克臻选上海烘焙工坊 中国上海,2020年10月 29 日 以设计主导的智能温控品牌Ember今天宣布,推出全新限量...





